IFRS9, PiTPD, and the Kalman Filter
Contents
Prior to the adoption of International Financial Reporting Standard 9 (IFRS9), provisioning were made only after exposures had turned delinquent. This “after-the-fact” shortcoming was heavily criticized for painting rosy pictures of the health of financial institutions before the 2008 Global Financial Crisis.
IFRS9 addressed the shortcoming by introducing the concept of expected credit loss (ECL). The calculation of ECL is quite daunting. One of the inputs that required in the calculation is the default probability of an obligor given a certain economic state. This is the so-called point-in-time PD (PiT PD).
One of the approaches of obtaining PiT PD is via Vasicek’s model. Specifically, Vasicek’s model postulates that PiT PD is given by
$$ \begin{equation*} PiT\ PD\ =\ N\left(\frac{N^{-1}( TTC\ PD) \ -\ s\sqrt{\rho }}{\sqrt{1-\rho }}\right) \end{equation*} $$
where:
- $ \displaystyle TTC\ PD $ is the PD average over the long-run;
- $ \displaystyle N $ is the cumulative standard normal distribution;
- $ \displaystyle N^{-1} $ is the inverse of the standard normal cumulative distribution;
- $ \displaystyle \rho $ is asset correlation;
- $ \displaystyle s $ is the common factor all obligors are subjected to. Further more, $\displaystyle s \ \sim \ N\left( 0,\ 1\right) $.
PiT PD is conditioned on $ \displaystyle s $. Therefore, $ \displaystyle s $ can be interpreted as economic state. The challenge of getting $ \displaystyle s $ is two folds:
- $ \displaystyle s $ has a specific form as required by Vasicek’s model, that is, $ \displaystyle s \ \sim \ N\left( 0,\ 1\right) $. This is very different from the usual economic variables; and
- $ \displaystyle s $ is economic state, which is not directly observable.
This post shows how $ \displaystyle s $ can be estimated using the Kalman Filter in R.
1.0 The Data
Due to the lack of long real GDP series in Malaysia (at the same constant prices), nominal GDP is used. The nominal GDP series spans 1963 to 2019. The analysis below uses the annual growth rate of the series.
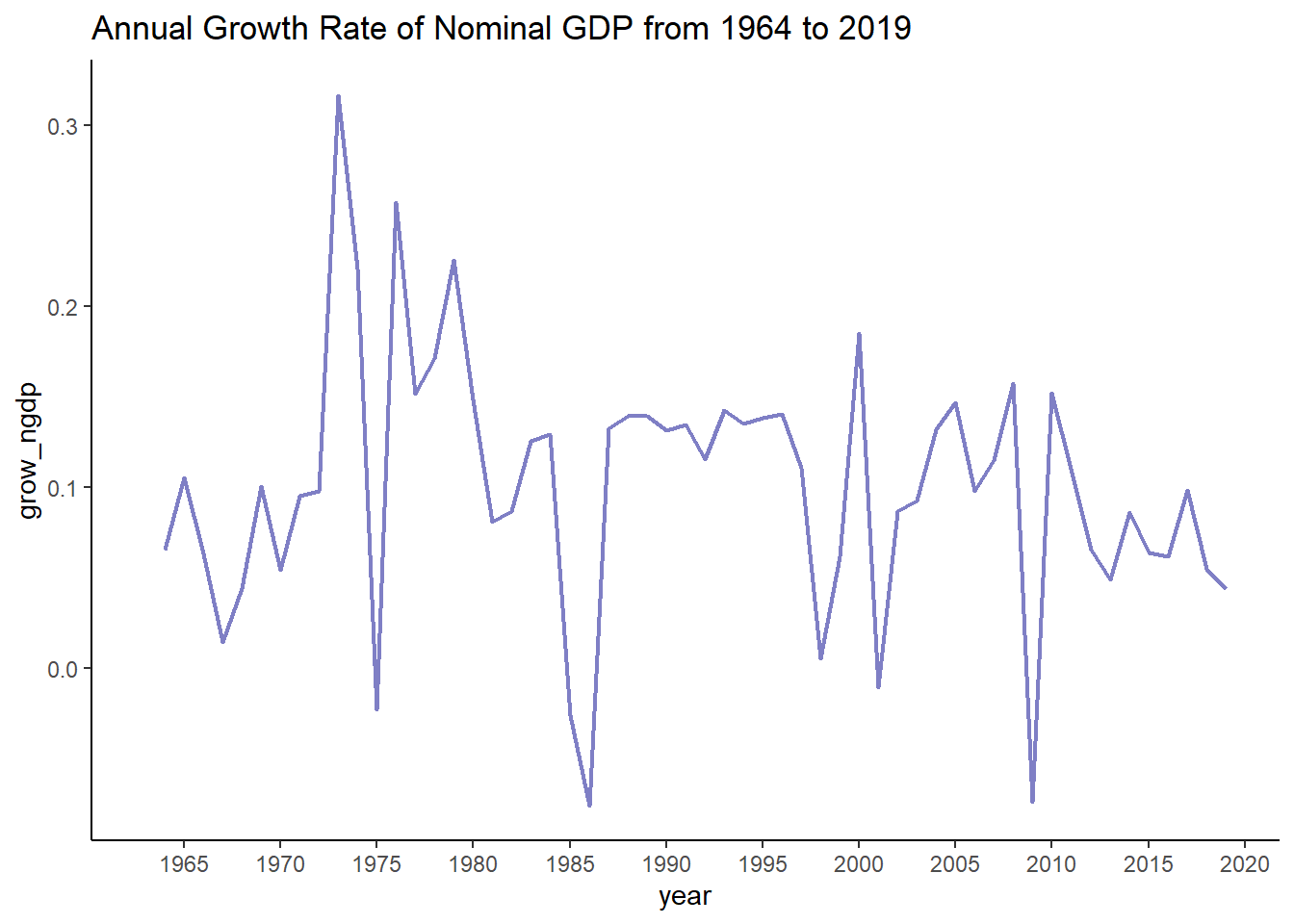
2.0 The Model
The annual nominal GDP growth rate is observable. However, it may not reflect the true state of the economy. The true state of an economy is not directly observable.
Let $ \displaystyle y_{t} $ be a variable that is directly observable and $ \displaystyle x_{t} $ be a variable that is not directly observable. $ \displaystyle x_{t} $ is called a state variable. To link these 2 variables together, a model in the state-space form can be written as:
$$ y_{t} \ =\ Ax_{t} + \ v_{t}\ $$ $$ x_{t} =\Phi x_{t-1} +\ w_{t} $$
where $ \displaystyle w_{t} \sim \ N( 0,\ Q) $ and $ \displaystyle v_{t} \sim \ N( 0,\ R) $.
The first equation is called the observation equation and the second equation is called the state equation. For the purpose of this post, the following conditions are imposed:
- $ \displaystyle y_{t} $ is the annual nominal GDP growth rate;
- $ \displaystyle x_{0} \ \sim \ N\left( 0,\ 1\right) $;
- $ \displaystyle w_{t} \ \sim \ N\left( 0,\ 1\right) $; and
- $ \displaystyle \Phi = 1 $
$ \displaystyle A $, $ \displaystyle \sigma_{v}^{2} $, and $ \displaystyle x_{t} $ need to be estimated. $ \displaystyle x_{t} $ is specified as a random walk process because its first difference is equal to $ \displaystyle w_{t} $, which is normally distributed with mean 0 and variance 1. The first-differenced $ \displaystyle x_{t} $ can then be used to substitute $ \displaystyle s $ in Vasicek’s model.
3.0 Estimation
The model in state-space form can be estimated using the Kalman Filter and the maximum likelihood approach. This is done below by using the astsa package in R.
The estimated values for $ \displaystyle A $ and $ \displaystyle \sigma_{v} $ are -0.07 and = 0.02, respectively.
|
|
|
|
|
|
|
|
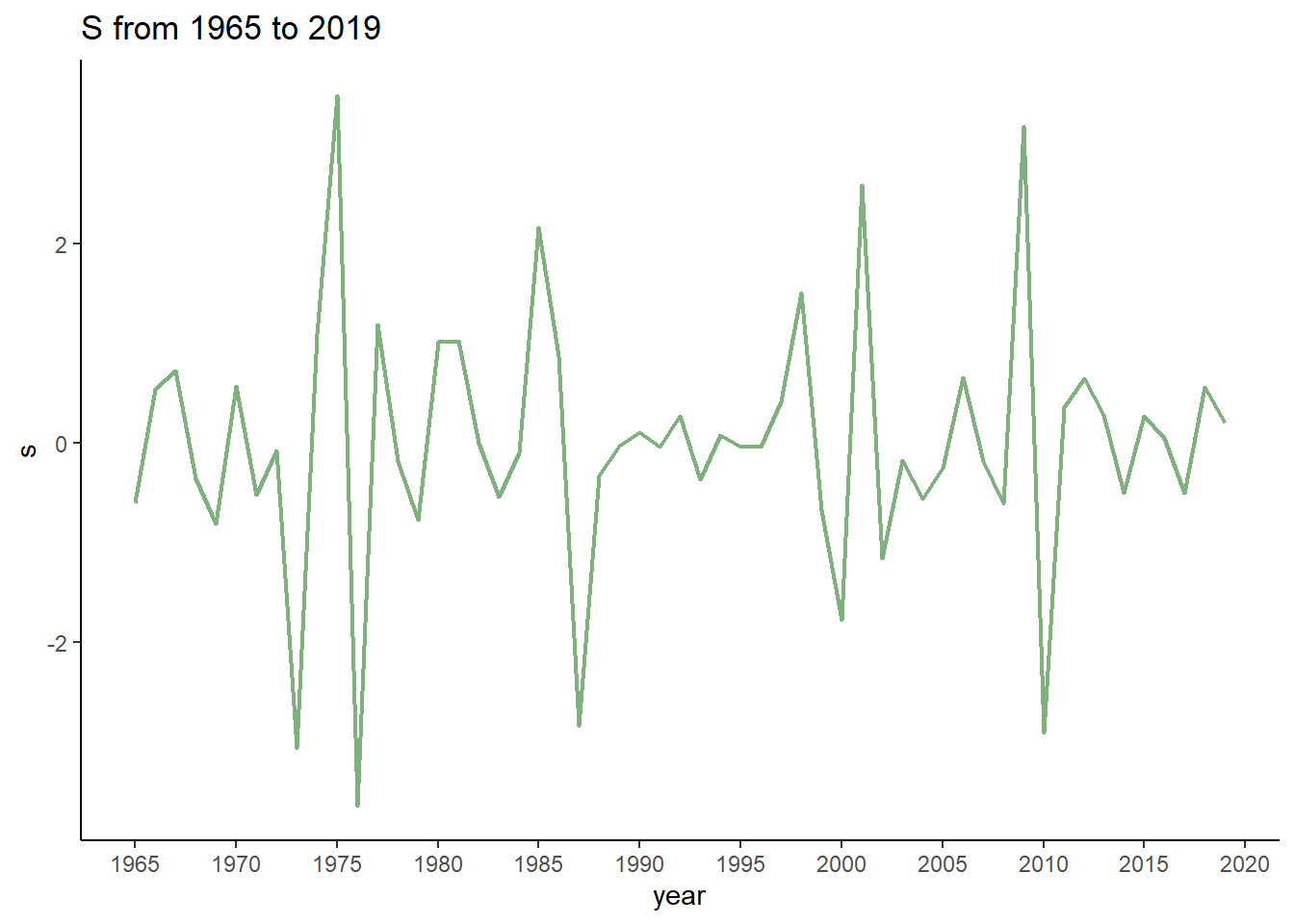
Next, the following codes are used to obtain $ \displaystyle x_{t} $ and then first-difference is applied on $ \displaystyle x_{t} $. The resulting series is called $ \displaystyle s $.
$ \displaystyle s $ can be selected based on the year and plugged into Vasicek’s model for the calculation of PiT PD (together with other inputs).
|
|
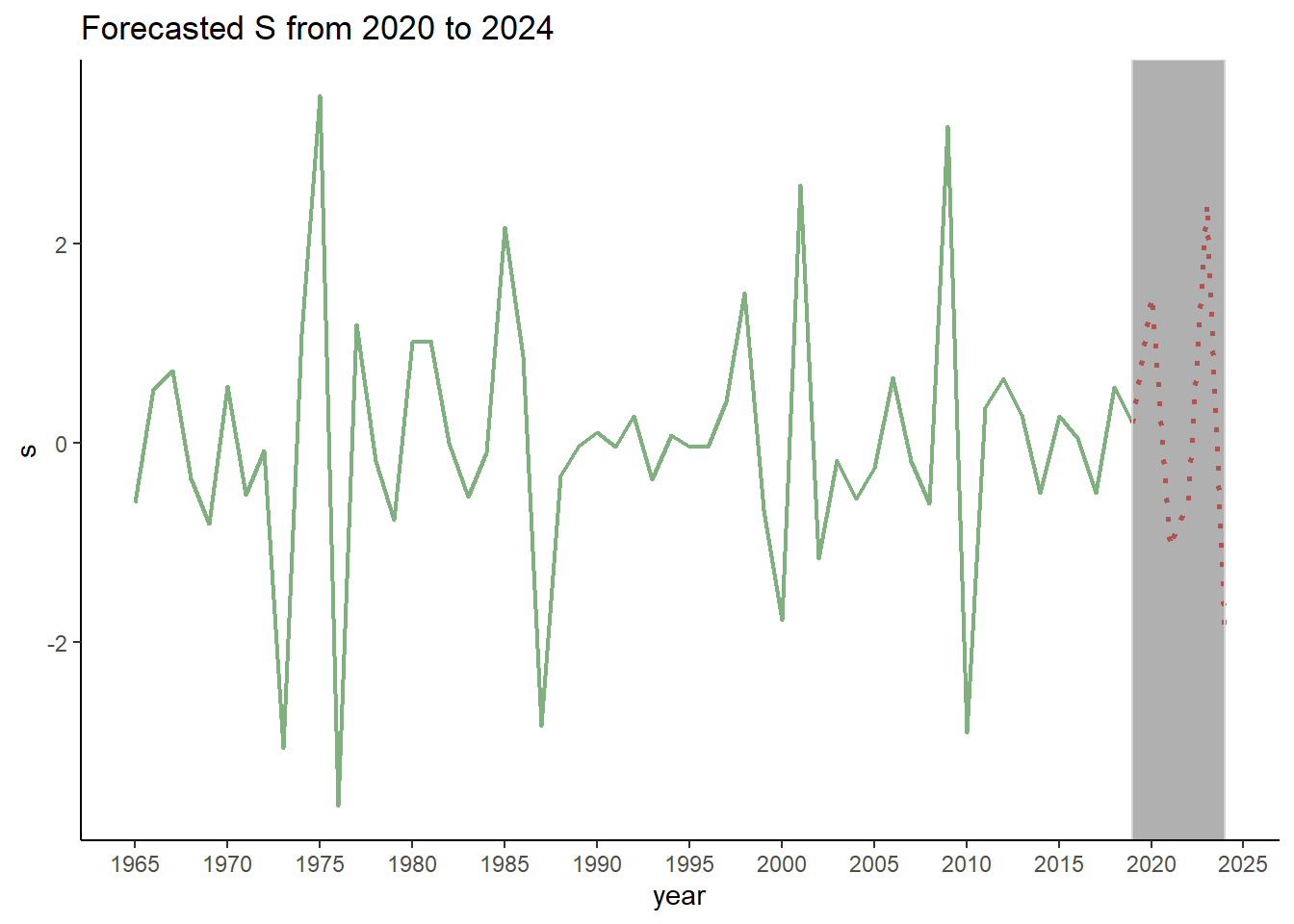
4.0 Forecasting
For the application in IFRS9, in-sample $ \displaystyle s $ is insufficient as PiT PD is needed over the lifetime of an exposure. This suggests that forecasted values of $ \displaystyle s $ are needed. As it turns out, the Kalman Filter has the forecasting algorithm built-in. This algorithm can be used, provided that the out-of-sample observable variable’s values are available. The codes below randomly generate out-of-sample $ \displaystyle y_{t} $ and then generate the forecasted $ \displaystyle s $.
|
|
5.0 Complex Model
A much more complex model can be specified. Suppose that the observable variable $ \displaystyle y_{t} $ follows an ARMAX(1,1) process and $ \displaystyle x_{t} $ follows an ARIMA(1,1,0) process. Then, the model is:
$$ y_{t} \ =\ \beta_{1}\ + \beta_{2} s_{t} \ +\ \beta_{3} y_{t-1} \ +\ \beta_{4} \epsilon _{t-1} \ +\epsilon _{t}\ $$ $$ x_{t} \ =\ x_{t-1} +\ \eta _{t} \ \ $$ $$ \epsilon _{t} \sim N\left( 0, \sigma ^{2}_{\epsilon }\right)\ $$ $$ \eta _{t} \sim N( 0,\ 1) $$
This model has been proposed by Chatterjee (2015). In state-space form, the model can be written as
$$ y_{t} \ =\ Ax_{t}\ $$ $$ x_{t+1} \ =\ \Phi x_{t} +\ \Upsilon u_{t} \ +\ \Theta v_{t} $$
where:
$\displaystyle A=\ \begin{bmatrix}
0 & 1 & 0
\end{bmatrix}$,
$\displaystyle x_{t+1} =\begin{bmatrix}
s_{t+1}\
y_{t}\
\beta_{4}\epsilon_{t}
\end{bmatrix}$,
$\displaystyle \Phi =\begin{bmatrix}
1 & 0 & 0\
\beta_{2} & \beta_{3} & 0\
0 & 0 & 0
\end{bmatrix}$,
$\displaystyle \Upsilon =\begin{bmatrix}
0 & 0 & 0\
0 & \beta_{1} & 0\
0 & 0 & 0
\end{bmatrix}$,
$\displaystyle u_{t} =\begin{bmatrix}
0\
1\
0
\end{bmatrix}$,
$\displaystyle \Theta =\begin{bmatrix}
1 & 0 & 0\
0 & 1 & \beta_{4}\
0 & \beta_{4} & 0
\end{bmatrix}$, and
$\displaystyle w_{t} =\begin{bmatrix}
\eta_{t+1}\
\epsilon_{t}\
\epsilon_{t-1}
\end{bmatrix}$.
There are 5 parameters (i.e $ \displaystyle \beta_{1} $ to $ \displaystyle \beta_{4} $ and $ \displaystyle \sigma ^{2}_{\epsilon} $) to be estimated in this model.
|
|
|
|
|
|
|
|
|
|
From the graph below, it can be seen that downturns as suggested by relatively large negative values of $ \displaystyle s_{t} $ are quite consistent with those generated by the simple model.
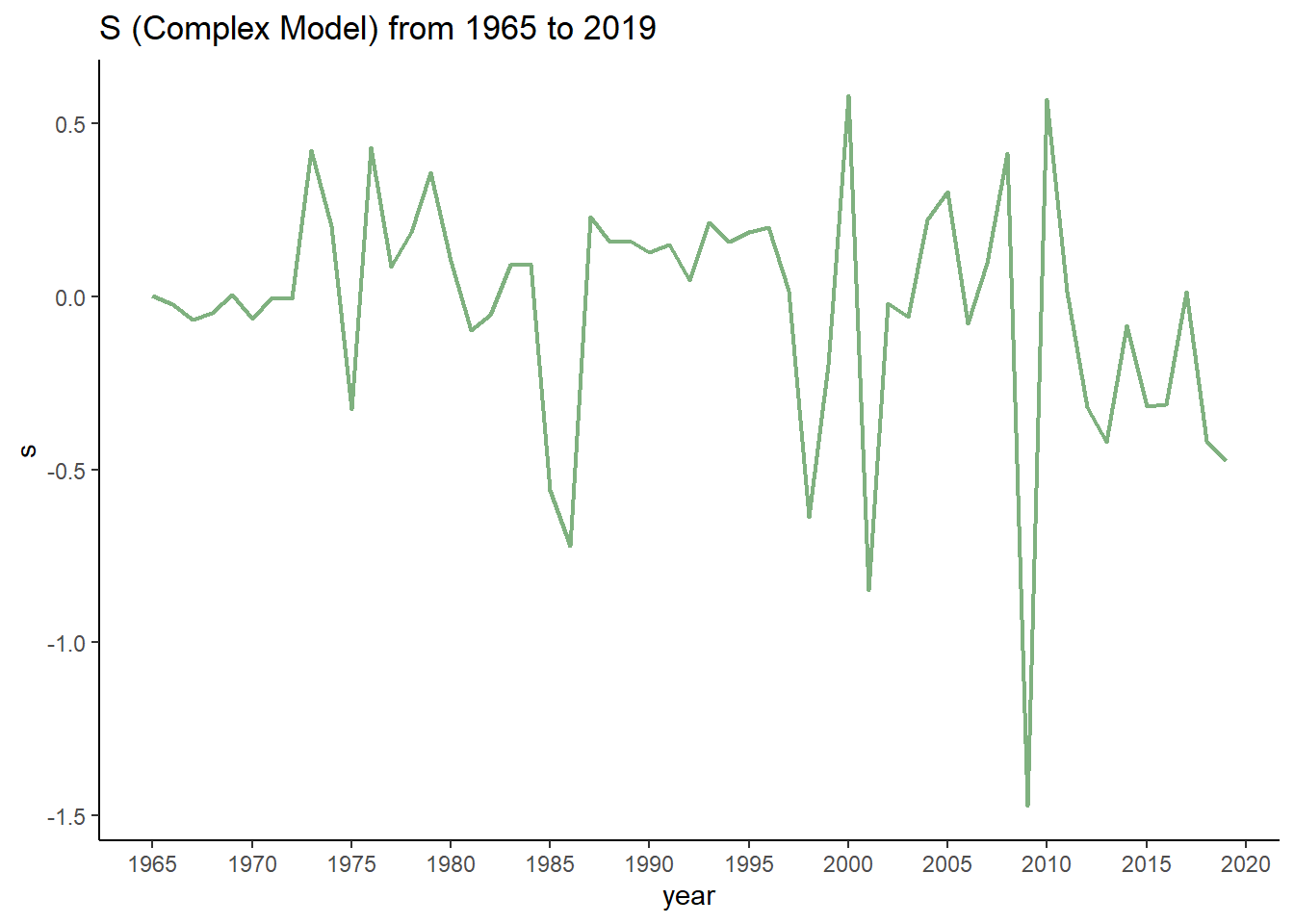
note
The forecasting algorithm for the complex model is different and is more complicated. Its analysis is omitted.
6.0 Conclusion
The Kalman Filter can be a handy tool for obtaining the required input for PiT PD calculation. However, for complex models, putting the models in state-space form could be a challenge. Another point worth mentioning is when estimating a complex model, the selection of initial values are critical.