Credit Scoring Development Using R - Part 3
Contents
This is the final part of a 3-parts series.
6.0 Regression Analysis
The ground is now set for developing a credit scorecard. The technique, as widely documented in the literature, is based on logistic regression. To obtain a parsimonious logistic regression, one approach is to use the stepwise method. This method seeks to minimize the AIC by allowing variables to enter or to exit iteratively.
Each type of method has its own pros and cons and this will not be discussed here. Regardless of which type of method is used, it should be viewed as a tool that allows an analyst to keep the task more manageable. Significant amount of manual adjustments and judgments are still needed to be made in order to arrive at the final credit scorecard.
The codes below perform stepwise logistic regression analysis. The stepwise method produces a logistic regression with 6 variables (max_util_l6m is excluded). All 6 variables are significant at the 5% level and all coefficients are positive. To keep things simple, the resulting logistic regression is taken as final.
|
|
|
|
The output from the VIF analysis does not suggests any multi-collinearity issue.
|
|
|
|
7.0 Scorecard Creation, Scaling, and Validation
Lastly, with the regression obtained, a credit scorecard can be created and validation exercise can be conducted.
The scaling used in this post is:
- at score of 500, the good bad odd is 100 and;
- the point of double odds (PDO) is 30. Moreover, the base score (i.e. intercept of the regression) is distributed evenly across the 6 variables.
The package scorecard can generate a full-blown report that contains variables statistics, score distribution, scaling information, performance indicators and validation results.
Danger
In the codes below, PDO has to be set as -30. This is because positive = 0. And since positive = 0, anything that labeled as good in the report are actually referring to bad, and anything that labeled as bad are actually referring to good. Likewise, bad rate should be interpreted as good rate.
|
|
|
|
|
|
|
|
|
|
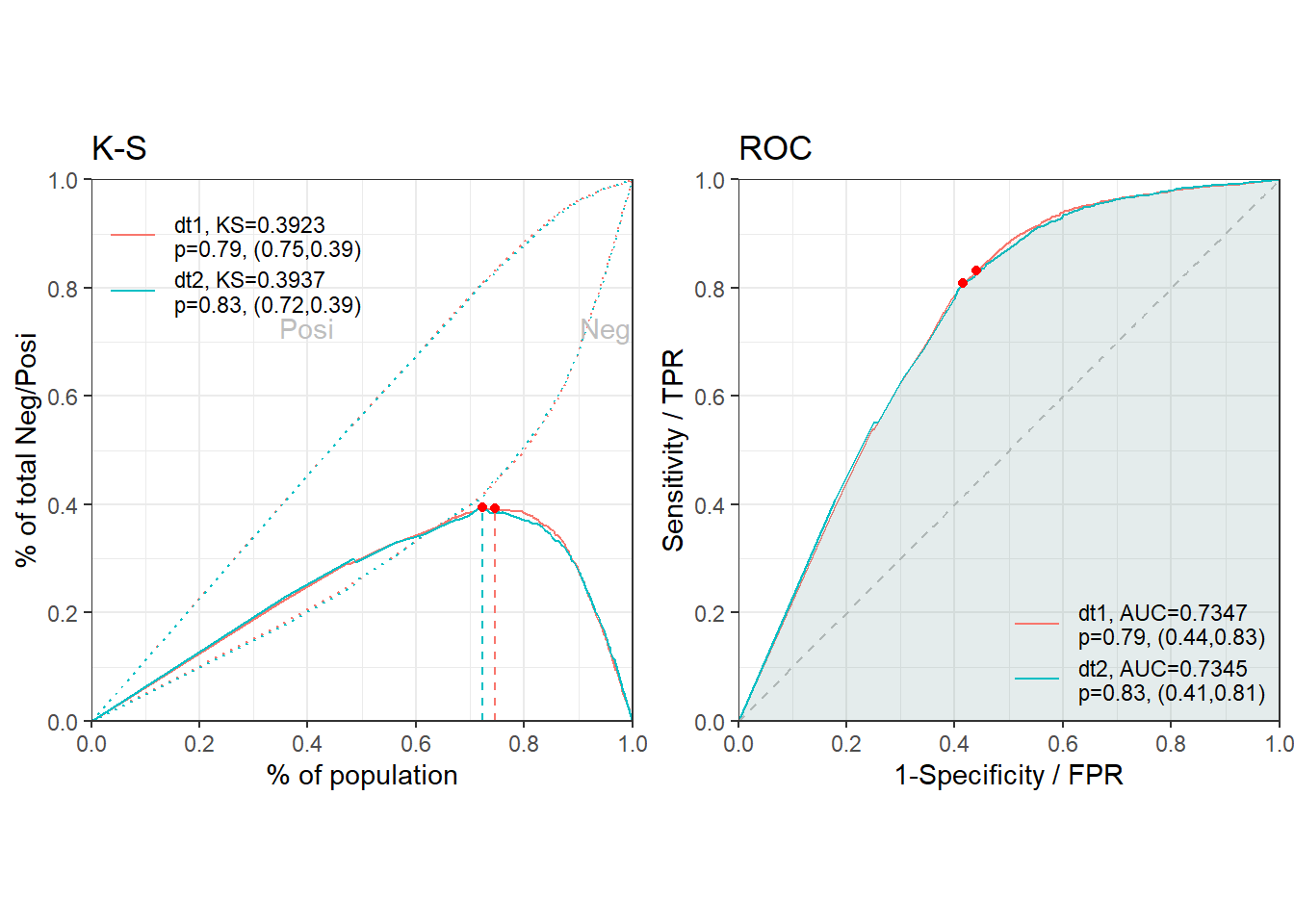
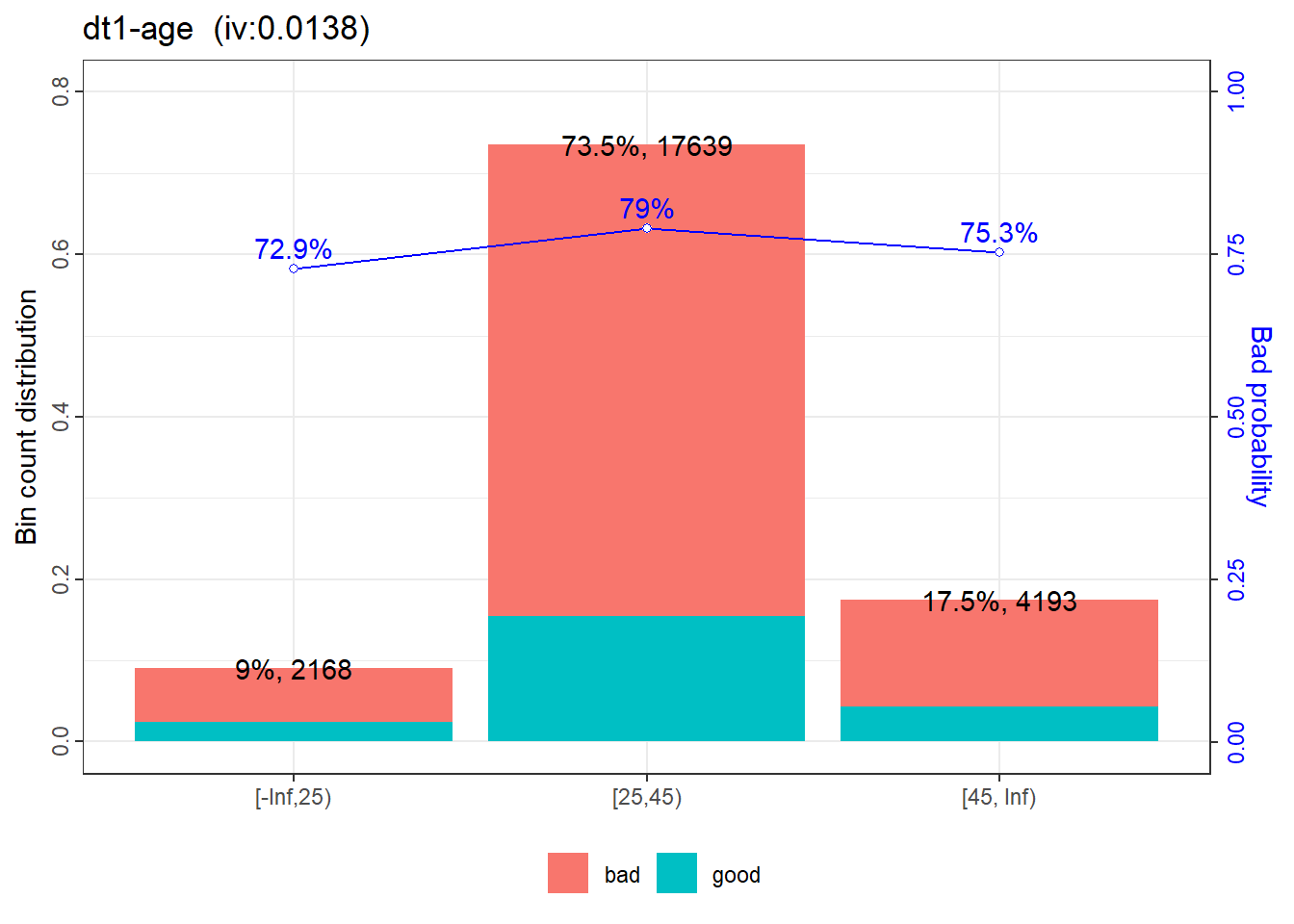
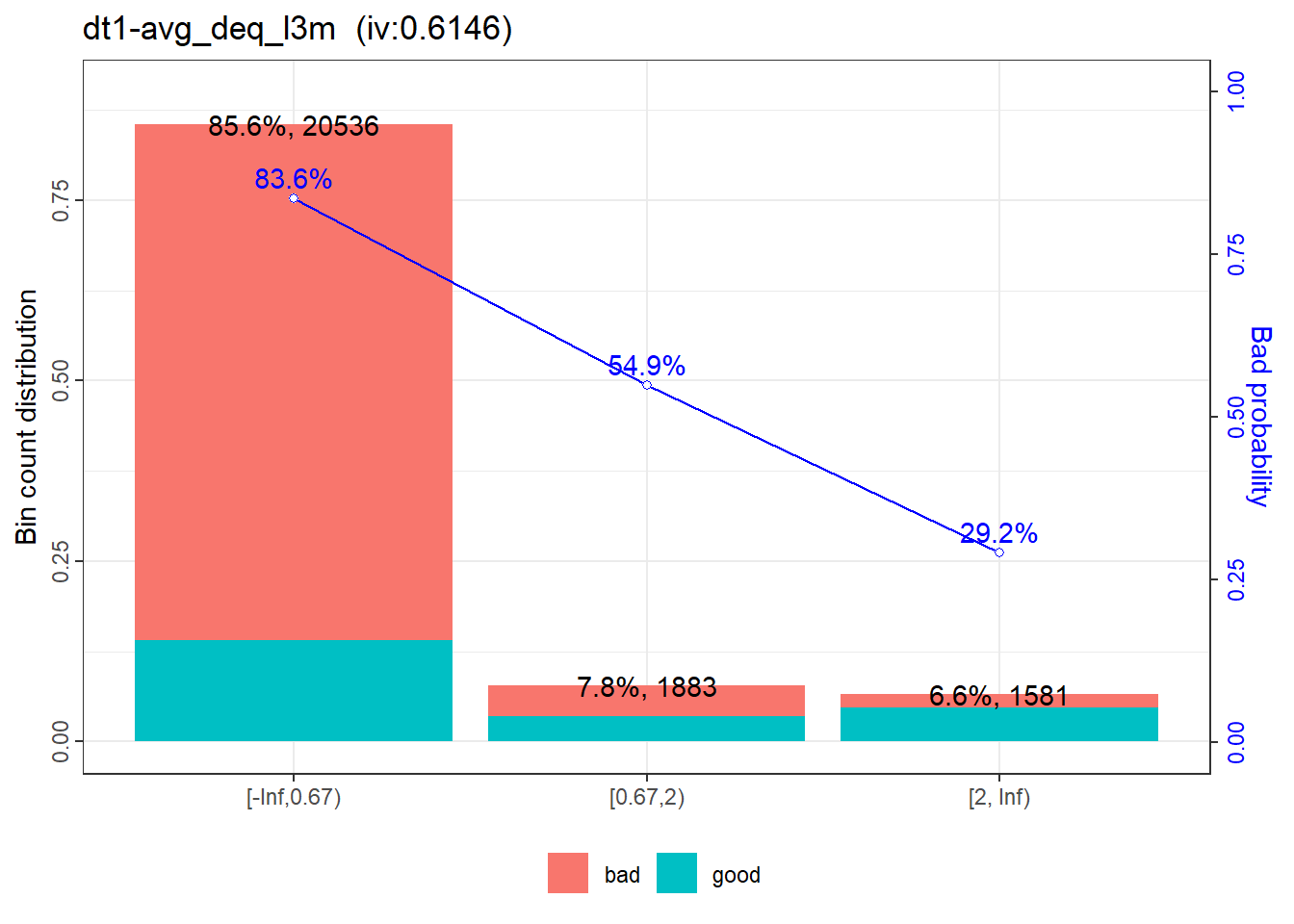
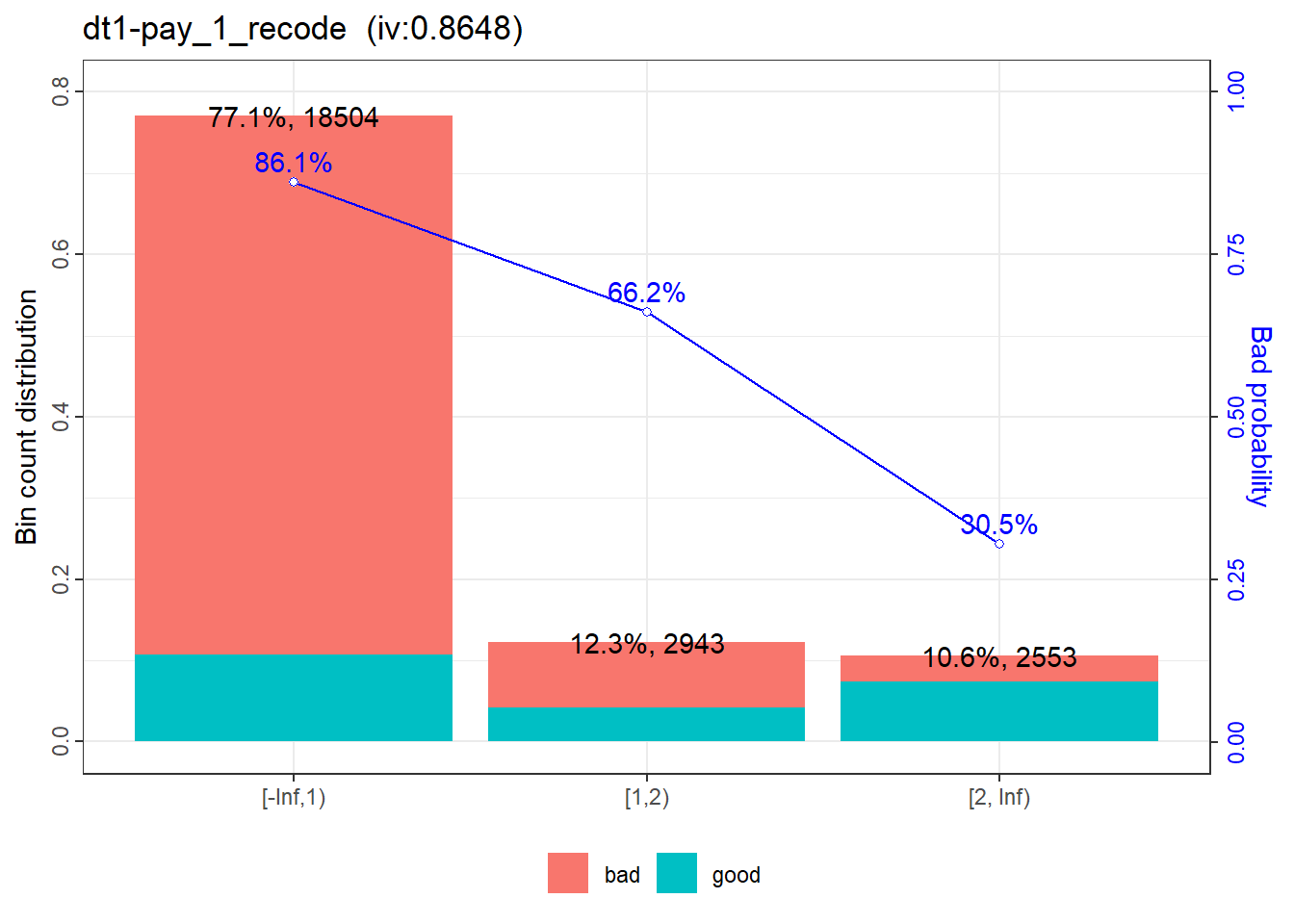
The validation report will be saved in the work directory.
|
|
|
|
|
|
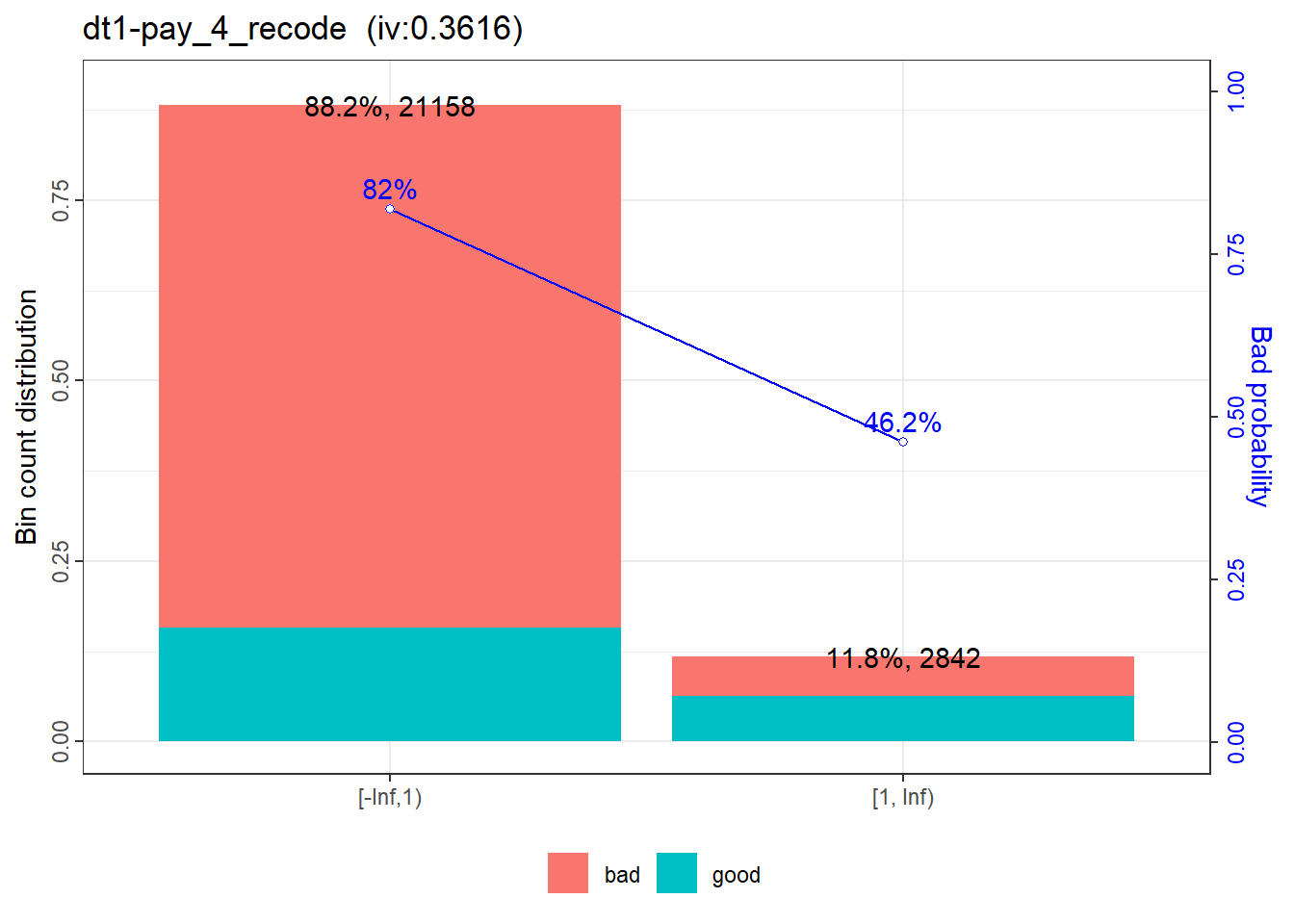
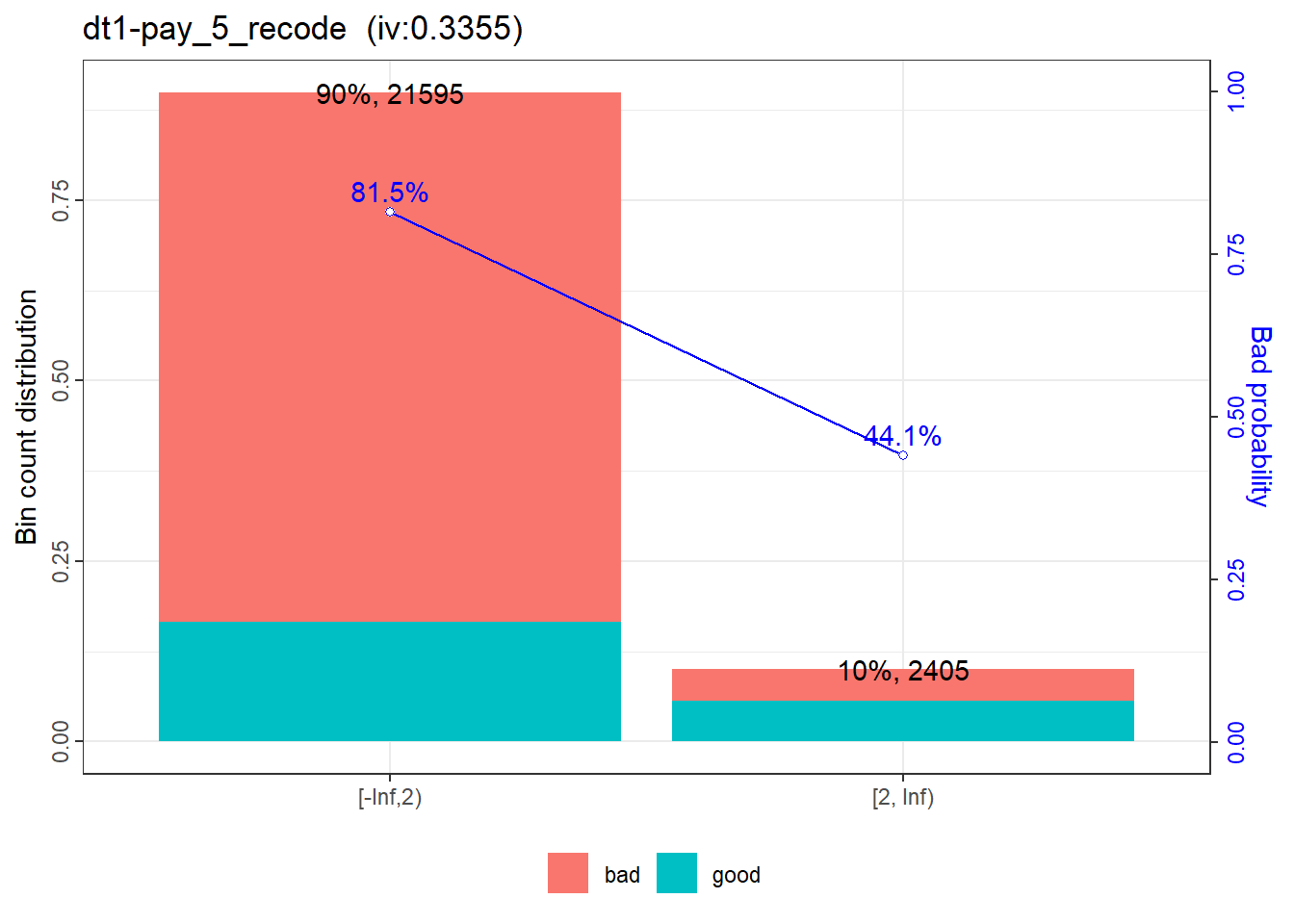
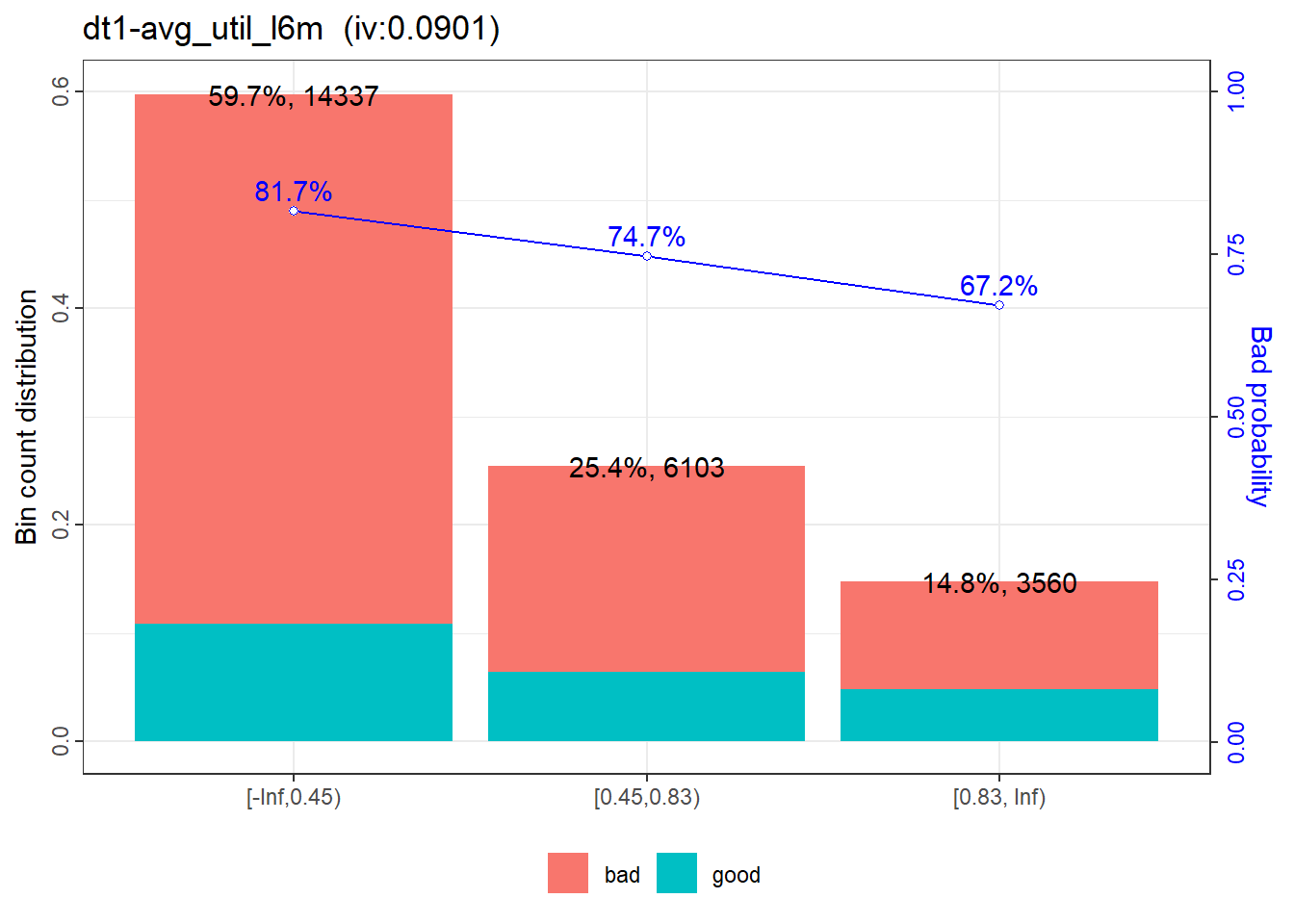
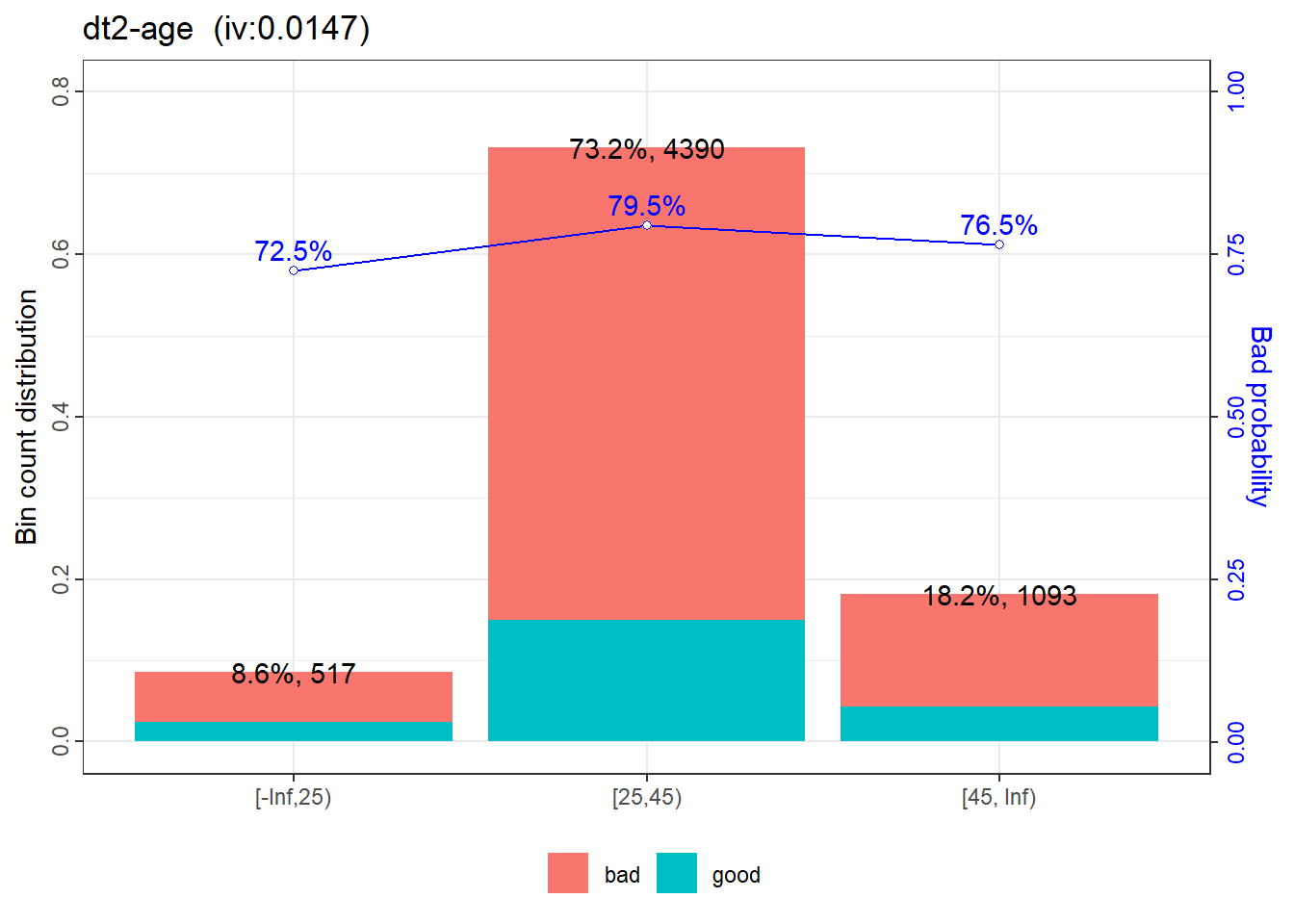
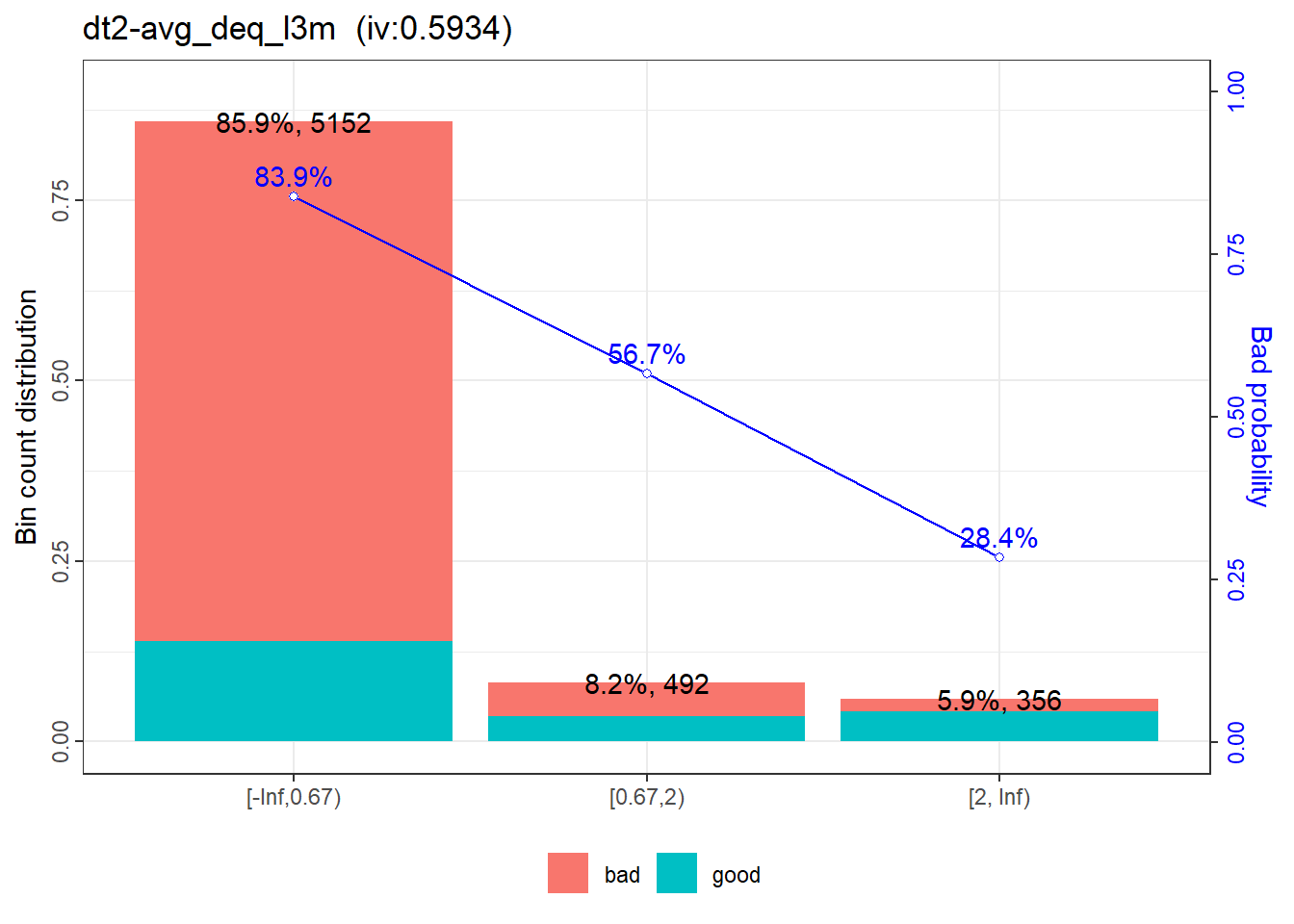
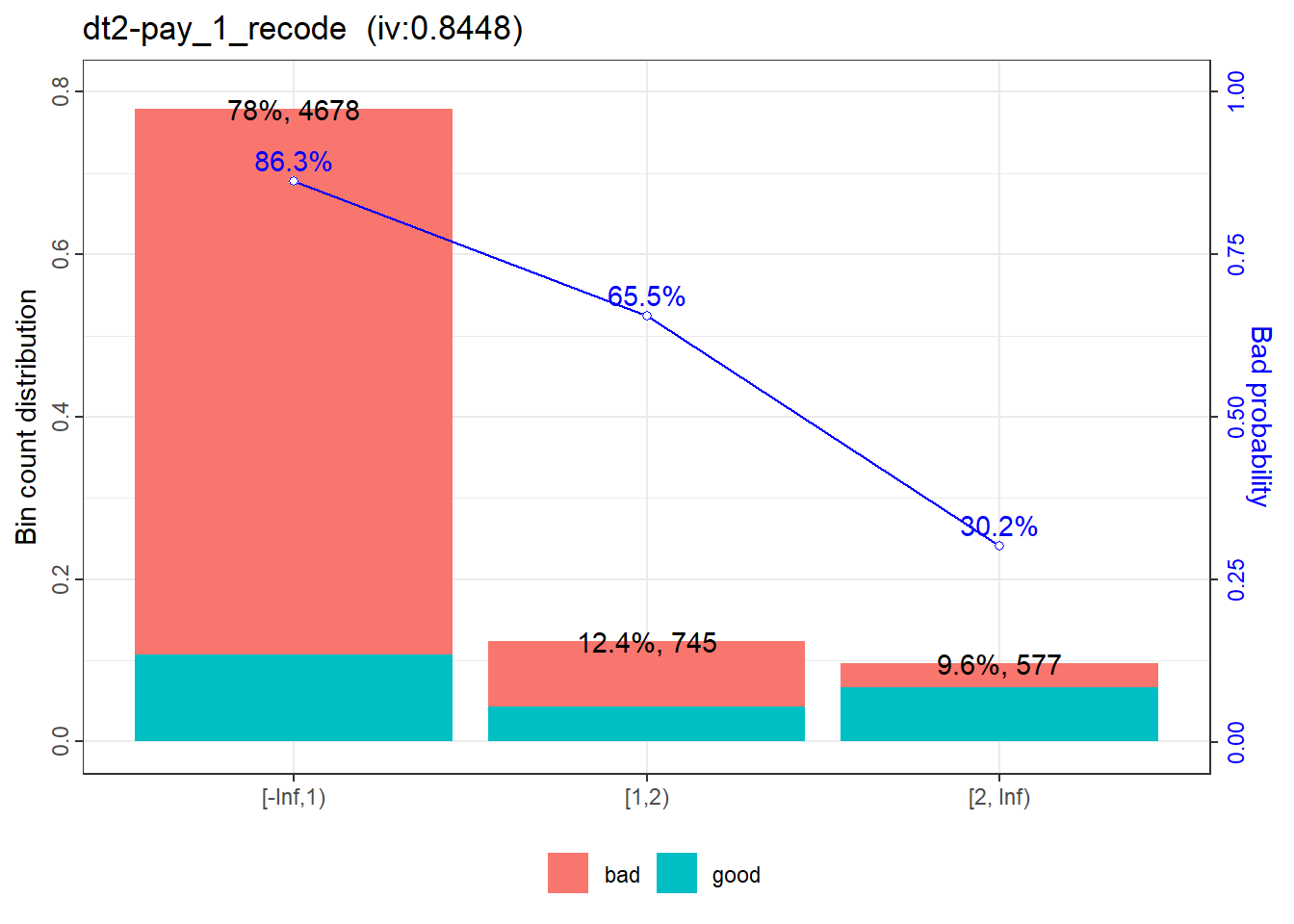
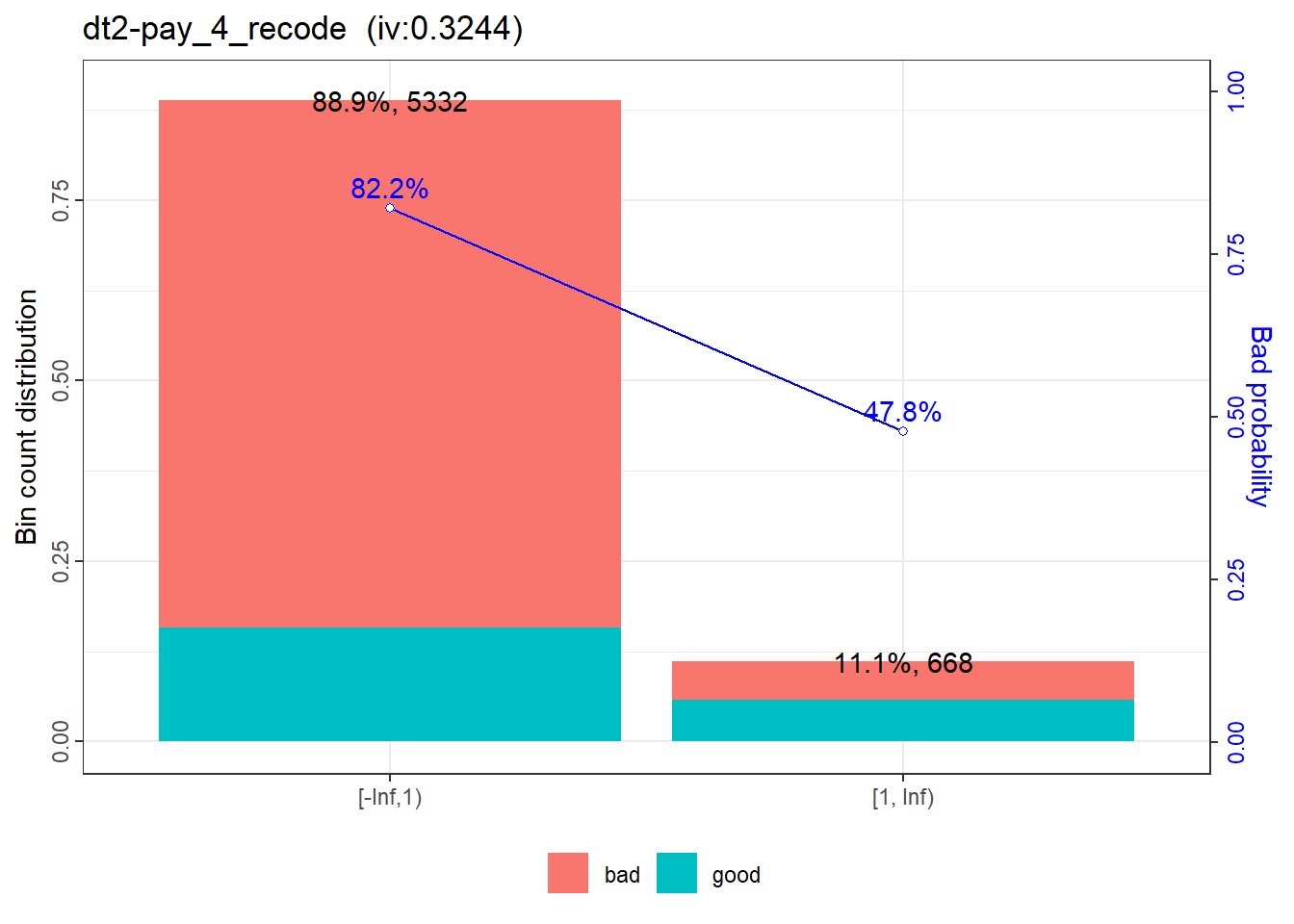
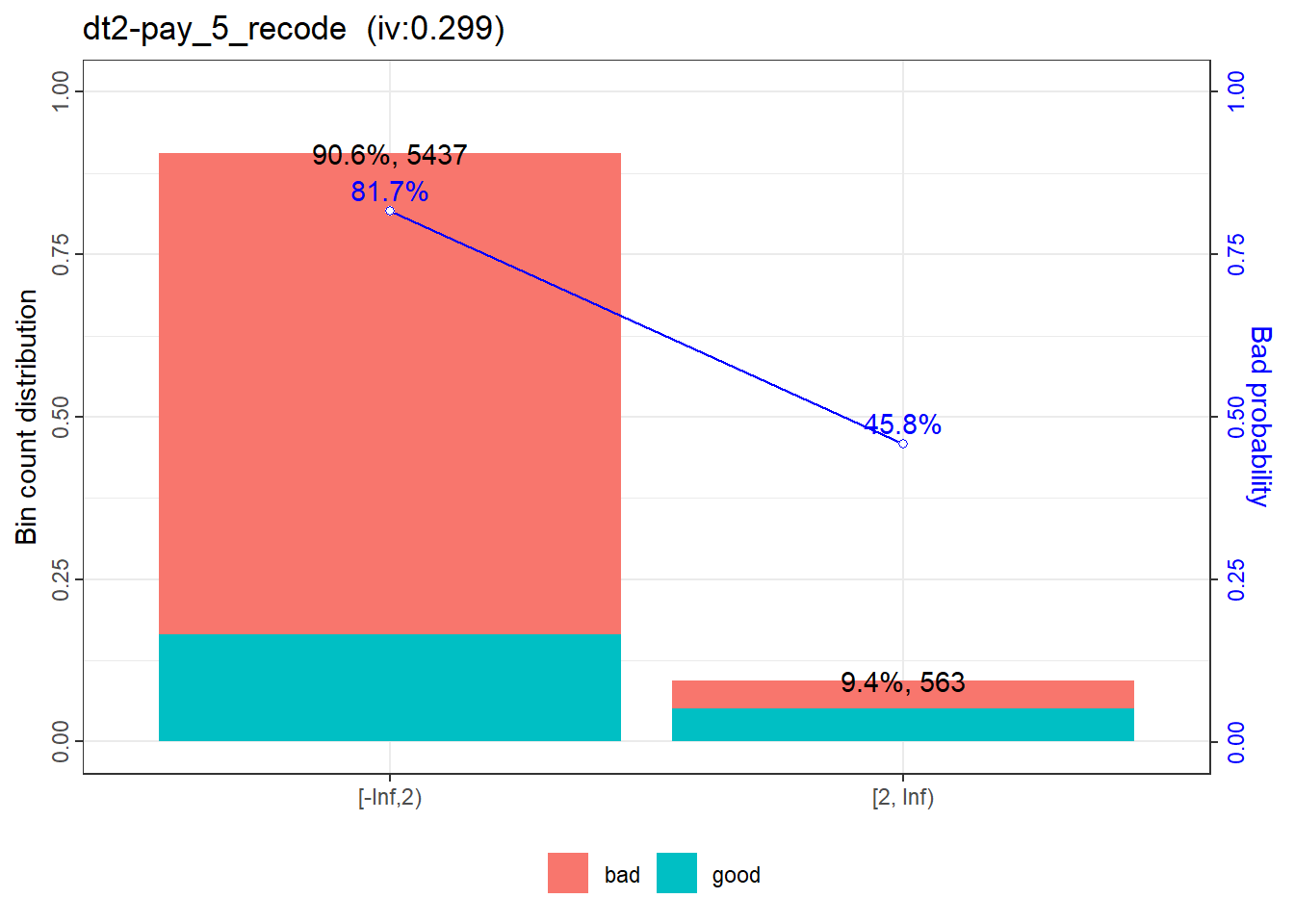
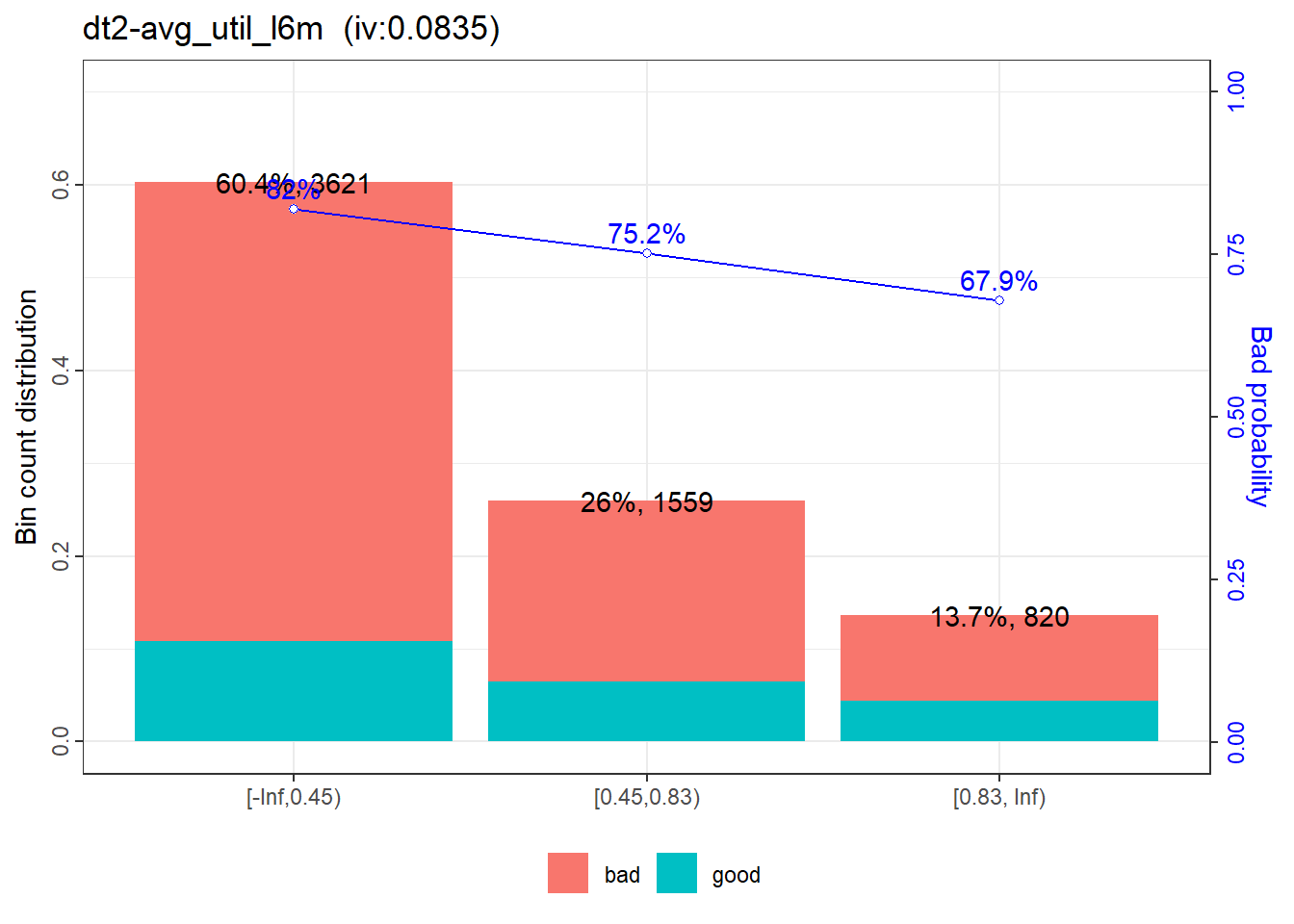
|
|
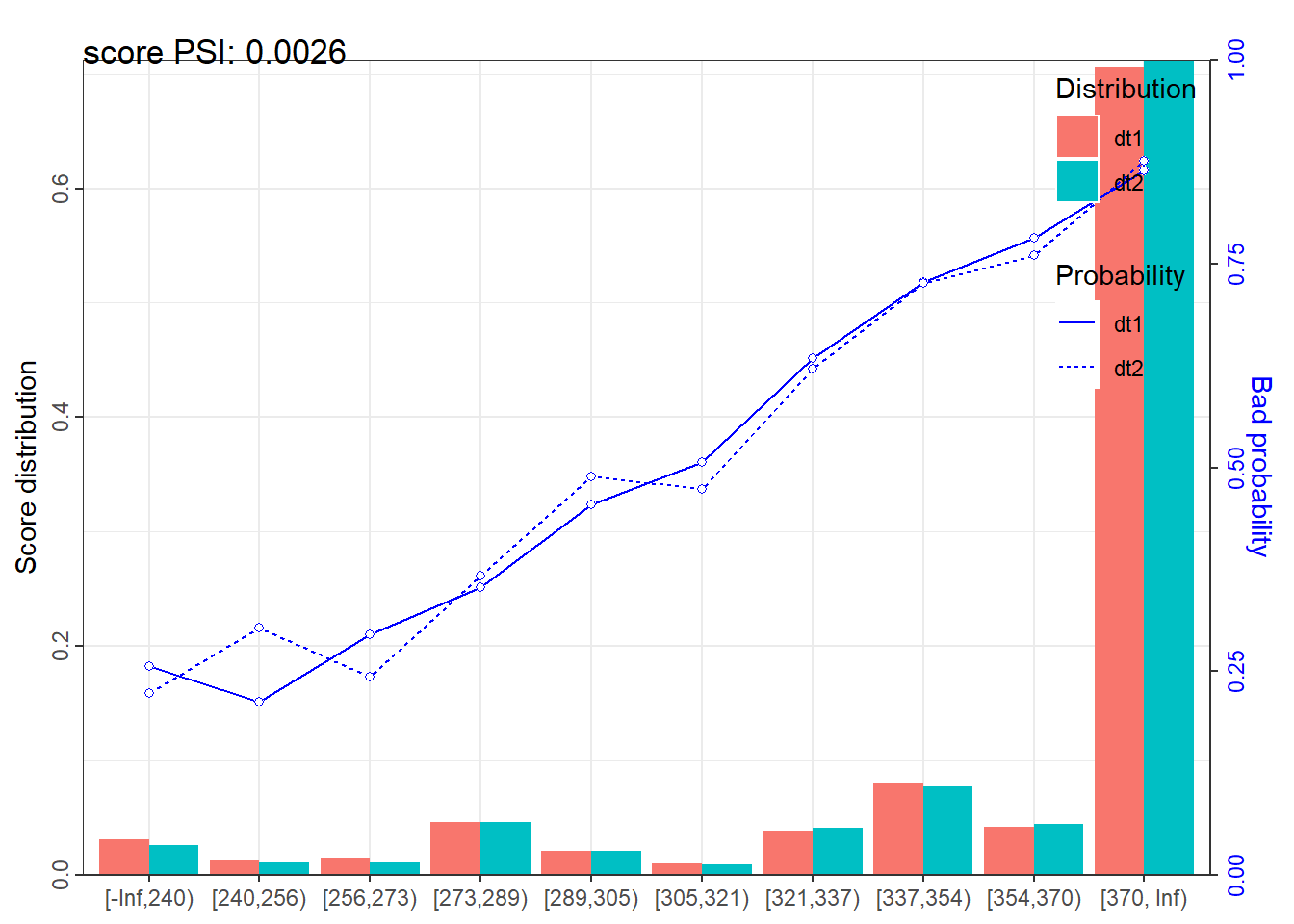
|
|
8.0 Conclusion
This post shows that a credit scorecard can be developed with ease in R using the package scorecard. The caveat is in the data set. The data set used in this post is small and clean, therefore, does not need a lot of cleaning and manipulations. The number of new variables that can be generated from the data set is also not huge.