V-fold Cross Validation and Variables Derivation
Contents
In a predictive modeling project, one of the issues that an analyst always encounter is over what time period should a variable be derived. For example, should the analyst derive 3-month historical utilization rate to predict future default, or 6-month historical utilization rate is more appropriate.
Usually, when deriving variables over time period makes sense, the analyst would settle on 4 time periods: 3-month, 6-month, 9-month, and 12-month. And then, based on some predictive performance metrics such as information-value (IV) or AUC, one variant of the derivation is short-listed for the next stage of the model development process.
This approach is problematic. First, the selection of 3, 6, 9 and 12-month periods are judgmental, even though it is a common practice among practitioners. Second, when the variants are assessed using performance metrics, one particular variant could be better than the others simply due to over-fitting, which cannot be generalized to the yet-to-be-seen samples.
While tempting, the second point cannot be resolved by using the validation sample1 that has been set aside for the evaluation of the final model. If the validation sample is used, then data leakage is introduced, which means that data outside the development sample is used to develop the model.
1.0 v-fold Cross Validation
This is an issue where cross validation can address. The figure below depicts the scheme of a 10-fold cross validation (v = 10). In essence, a 10-fold cross validation divides the development sample into 10 parts. In each fold, 9 parts are used for analysis and the remaining 1 part is used for testing. A testing part is technically a validation sample but the data does not come from the actual validation sample. Therefore, there is no data leakage in this approach. In addition, a testing sample covers different, non-overlapping region of the development sample as it iterates across different folds. Consequently, the performance metrics computed based on the testing samples will be free of over-fitting issue.

2.0 Data
The data is a data set on Taiwan’s credit card holders. It is sourced from UCI Machine Learning Center and a cleaned version can be obtained from Github.
|
|
To keep the analysis short and focus, only a few columns from the data set are selected.
|
|
3.0 Sample Splitting
In this section, the initial sample is split and the folds of cross validation are generated.
|
|
|
|
The initial_split function in the tidymodels package splits the initial sample into a development sample of 22,500 credit card holders and a validation sample of 7,500 credit card holders. The vfold_cv function with option v = 10 creates 10 folds for cross validation from the development sample. 10 is a normally chosen value, but v can be higher or lower.
|
|
|
|
4.0 10-fold Cross Validation
Cross validation is conceptually simple. But when it comes to implementation, it is not so straight forward as it involves many samples (i.e. folds) and multiple variables/models.
The analysis makes use of the scorecard and the tidymodels packages to:
scorecard: compute the IVs of the variants;tidymodels: iterate over different folds and different variants.
As the codes can be hard to understand, it would be best to first describe how iterations work with the use of tidymodels. The function that is used is map. In the simplest form, map takes a list as the first argument and a function as the second argument. What map does is applying the function on each of the elements in the list. The following figure depicts the iteration. map2 works in the same way but takes 2 lists as inputs.

For each fold, the process is:
- compute the IVs of the variants in the training sample;
- save the break points that used for IV computations in step 1;
- apply the break points on the testing sample and compute the IVs.
|
|
|
|
|
|
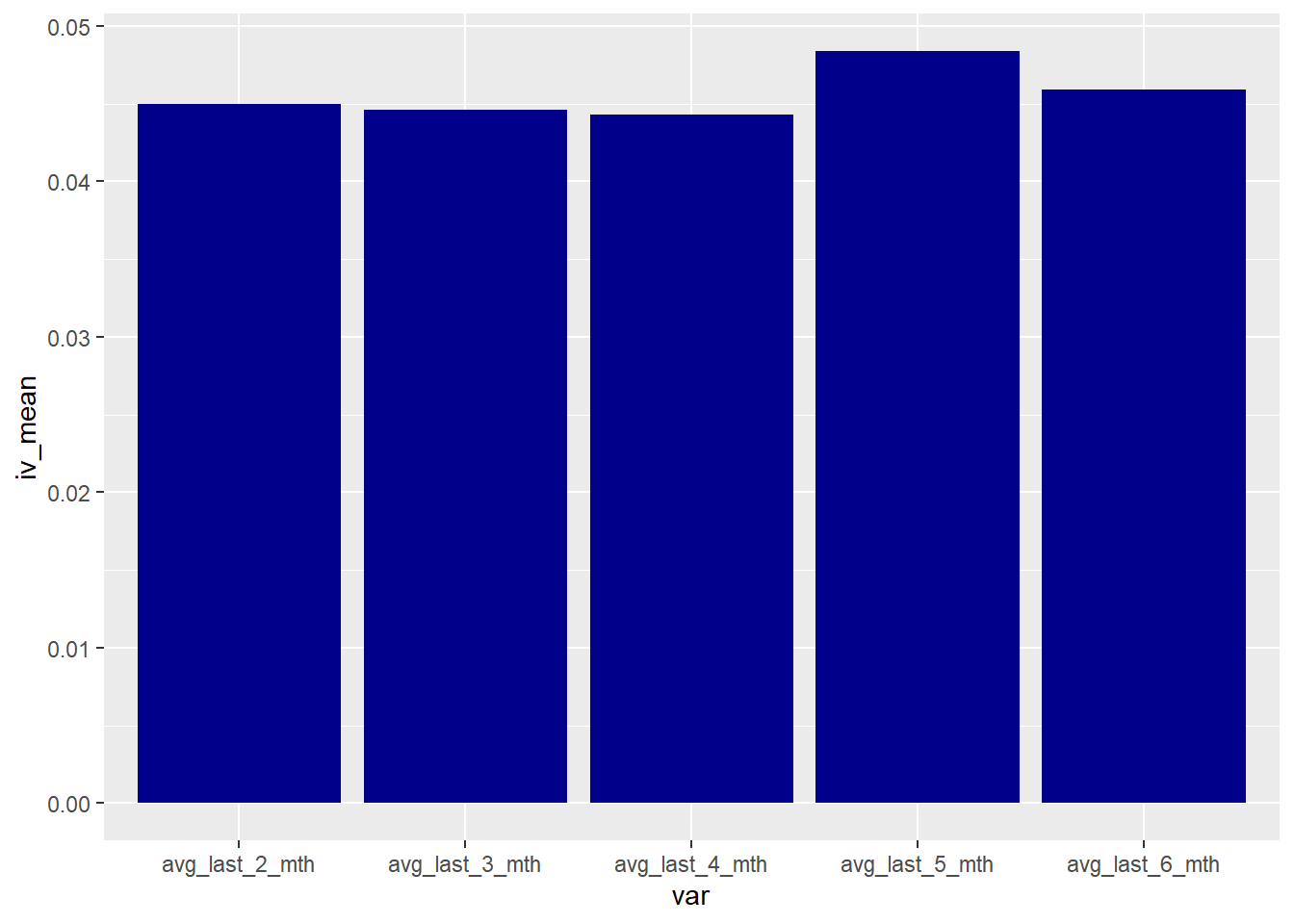
5.0 Conclusion
The analysis shows that the usual time periods used for variables derivations can be sub-optimal. The approach shown here essentially treats time period as a tuning parameter and use v-fold cross validation to determine the optimal parameter. In addition, v-fold cross validation eliminates any doubts on over-fitting and avoid data leakage. With some modifications, the approach can be applied in a wide range of applications.
-
To make the terminology clear, the definitions of different samples are given. The full, un-split sample is the initial sample. The initial sample can be split into a development sample and a validation sample, on a ratio of 80:20 or 75:25 etc., with the larger percentage goes to development sample. ↩︎